Chapter 0 — Introduction: From Using Tools to Understanding Systems
Lately, I’ve been reflecting more seriously on the systems I build. Not just when everything works perfectly—but when they start scaling, handling more data, or behaving in unexpected ways.
The more I think about it, the more I realize something simple:
There’s a lot happening under the hood that I don’t fully understand yet.
That’s what pushed me to pick up Designing Data-Intensive Applications by Martin Kleppmann.
It made me pause. I’ve been building with solid tools and real architectures, but I hadn’t really stepped back to think about the trade-offs behind them—why some systems scale smoothly while others become fragile as they grow.

The Buzzwords We Hear (But Don’t Always Understand)
Walk into any tech discussion today, and the buzzwords are everywhere:
NoSQL, Big Data, Sharding, CAP Theorem, Eventual Consistency, Real-time Processing…
At some point, they start to feel familiar. But knowing the term is very different from understanding what it actually means in practice.
What happens when traffic suddenly spikes?
What happens when a service fails in production?
What happens when your data evolves faster than your system can handle?
That’s where real understanding begins.
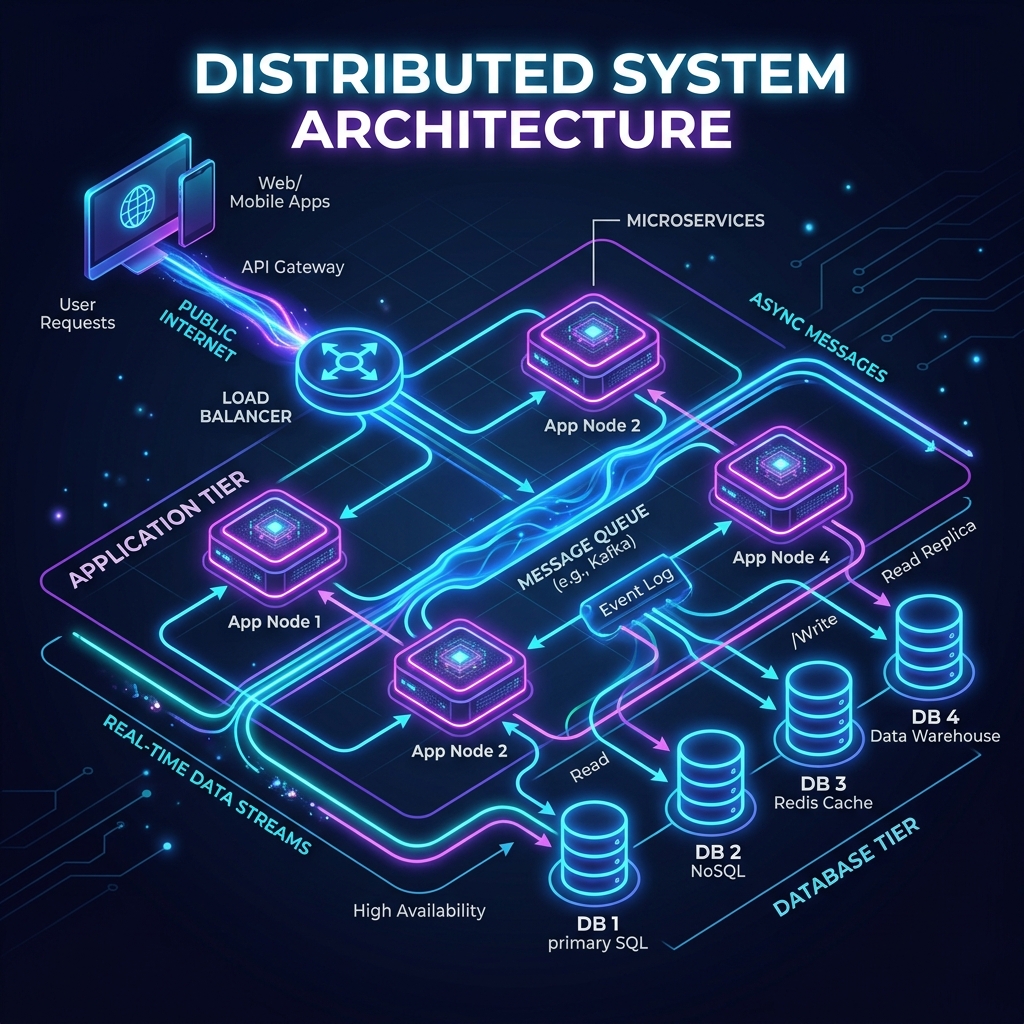
The Context We’re Building In
Backend systems today are very different from what they used to be.
Even small teams can now build systems that run across multiple machines or regions, process large volumes of data, and are expected to be always available.
Some major shifts explain this:
- Distributed systems are now the default, not something reserved for big tech companies.
- Cloud infrastructure has become the foundation, making it easier to scale, deploy, and manage systems globally.
- High availability is expected, where downtime quickly becomes a real business issue.
- Hardware keeps evolving, allowing more parallel processing and higher throughput.
- AI is becoming part of the development process, helping generate code and suggest solutions.
This is the environment in which modern systems are built.
Why This Matters to Me
For me, this is where things become more personal.
I want to understand how systems are built and how they actually work under the hood. Not just use tools or frameworks without really knowing what’s happening behind them.
It’s easy today to build things quickly using existing tools, libraries, or even AI. But I don’t want to depend on something I don’t fully understand.
And that’s not the kind of engineer I want to become.
I don’t want to just make things work. I want to understand:
- why a system behaves the way it does
- when it might fail
- what trade-offs I’m making when I choose a solution
That’s the real reason I decided to read this book.
What I Hope to Explore in This Series
Instead of just reading this book and moving on, I decided to turn it into a series.
My goal is simple:
- to explain what I learn in my own words
- to connect it to real systems I work with (APIs, microservices…)
- and to better understand the trade-offs behind technical decisions
In the upcoming posts, I’ll go through the book step by step:
- Foundations: reliability, scalability, and maintainability
- Distributed systems: replication, partitioning, transactions, consistency
- Data processing: batch and stream processing
This isn’t just theory—it’s about understanding the systems we build every day and improving how we design them.
What’s Next
Next, I’ll start with a simple but important question:
What does it really mean for a system to be reliable, scalable, and maintainable?
That’s where everything begins.
I’m still learning, but sharing this is part of the process.